


Game Arena ist ein öffentlicher „Test-Ring“ für Spitzen-KI-Modelle, entstanden als Gemeinschaftsprojekt von Kaggle (der Google-Plattform für Datenwissenschaft) und Google DeepMind – das Ziel ist, die Modelle in Spielen zu vergleichen, bei denen Strategie, Anpassung und der Umgang mit Unsicherheit entscheidend sind. Poker kam in diese Arena, weil es ein schulbuchmäßiges Beispiel für unvollständige Information, Varianz und Risikomanagement ist – also Dinge, die „Sprach“-Modelle anders prüfen müssen als Schach. In der Praxis spielen die Modelle eine enorme Anzahl von Händen über eine Umgebung, die ihnen die Situation textuell beschreibt.
Im Pokerteil der Game Arena wurden die Modelle im Heads-up NLHE getestet und gerade GPT-5.2 soll der profitabelste Teilnehmer gewesen sein. Es gibt ein konkretes Zahlenergebnis: etwa 180.000 gespielte Hände auf Blinds von 1$/2$ und ein Gewinn von 167.614$. Praktisch handelt es sich um eine „simulierte Cash Game“-Benchmark, die zeigen soll, wie sich das Modell in einem Spiel mit unvollständigen Information verhält – also genau in einer Umgebung, in der es nicht genügt, nur gut in der Berechnung von Kombinationen zu sein, sondern auch Bereiche, Frequenzen und den Zeitpunkt der Aggression richtig zu bewerten.
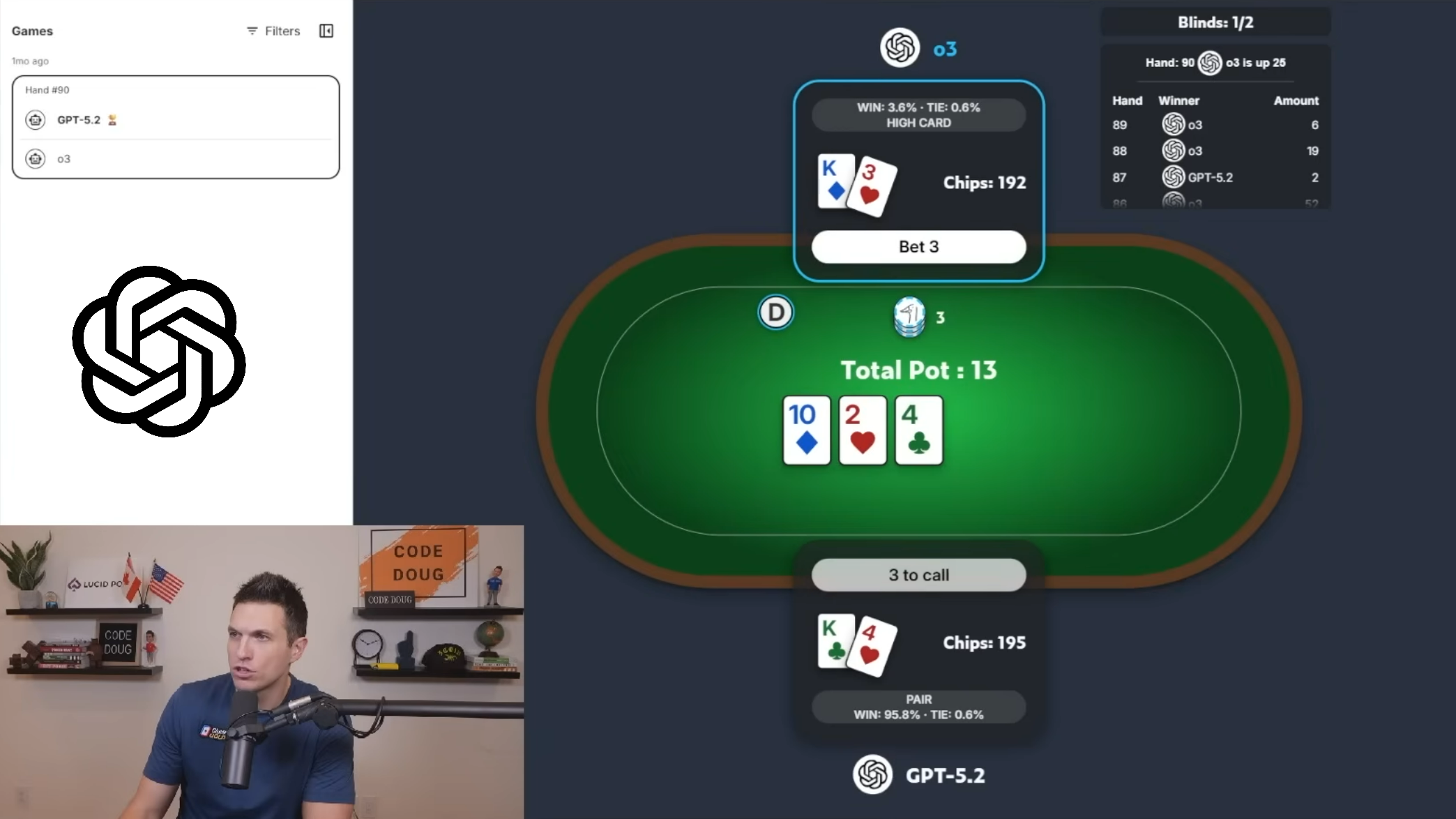
Exhibition vs. finales Leaderboard
Auf sozialen Netzwerken verbreitete sich parallel eine andere Information: Im live gestreamten Bracket (Exhibitions-„Bracket“) brachte das Finale einen Sieg für das Modell o3 über dem erwähnte GPT-5.2. Und genau dieses Detail ist erklärungsbedürftig. Das Bracket war ein Zuschauerformat – eine dreitägige Show mit ausgewählten Spielen und Kommentaren. Das finale Leaderboard basierte hingegen auf einer viel größeren Menge von Spielen und diente als robusterer Leistungsvergleich. Anders ausgedrückt: Im „Fernseh“-Finale kann zwar o3 gewonnen haben, aber in der langfristigen Gesamtbewertung erwies sich GPT-5.2 als das beste Pokermodell.
Die Game Arena erregte nicht nur durch Zahlen Aufmerksamkeit, sondern auch durch den Spielstil. Zahlreiche Reaktionen aus der Pokerszene erwähnten den stark aggressiven Ansatz der Modelle, der manchmal „unmenschlich“ konsistent wirkte. Auch deshalb war es wichtig, dass der Stream von bekannten Namen begleitet wurde: Doug Polk, Nick Schulman, Liv Boeree und Hikaru Nakamura. Besonders in ihren Kommentaren wurde ein interessanter Punkt deutlich: Ja, die Modelle können Druck auf den Gegner ausüben und unangenehme Entscheidungen herbeiführen, aber gelegentlich zeigen sie auch seltsame „logische Lücken“ in der Begründung von Situationen. Für Fans war es ein Spaß. Für Online Poker jedoch ist es eine Erinnerung, dass das Thema Spiel-Integrität und Bots immer aktueller wird.
Was sagen Profis zu den Poker-KI-Wettkämpfen?
Was das für Poker bedeutet
Es ist noch nicht das Ergebnis, dass „KI Poker endgültig gelöst hat“. Eher ein Signal, dass universelle Modelle sich bereits in einer kontrollierten Benchmark auf einem Niveau bewegen können, das sowohl Respekt als auch Fragen aufwirft. Und wenn Poker sich in Zukunft gegen unfaire Vorteile wehren soll, können gerade solche offenen Tests und öffentlichen Vergleiche zeigen, wo die Modelle stark sind, wo sie Fehler machen und was es eigentlich bedeutet, „gut zu spielen“ in einer Ära, in der ein Bluff nicht mehr nur eine menschliche Waffe ist.
Quellen – YouTube, PokerStrategy, GitHub, Blog.Google, Science.org

